entropy of English
This video on model scaling highlights an interesting point, which is to use the best models (nowadays LLM’s) to estimate the entropy rate of the source, in this case, the English language. This isn’t a new idea at all and empirical entropy measurements have been done in the past.
What’s interesting is that past estimates of bits per word of English have been way, way higher. Shannon’s original estimates are 11.82 bits per word, for example, or 2.62 bits per letter.
Some more recent estimates are understandably lower, like referenced in this Stackoverflow answer, which reports 5.7 bits per word. In this video we have the notion that the entropy of English is either undetectably low (which is impossible and suggests model overfit), or quite low, like 1.69 bits per token in this DeepMind paper.

Now, this video plays fast and loose with the units of what’s reported, so we need to be careful. What’s a token you say? This Stackoverflow answer says for several models it is “approximately 4 characters or 3/4 of a word”. This paper uses a research model called Chinchilla, and doesn’t say what is a token, but let’s take it to be the conventional 3/4 of a word. That makes the DeepMind result really 2.25 bits per word.
Then the next plot showing OpenAI’s GPT-4 performance from their Technical Report is even more extreme, showing, so far as I can tell from the graph, between 1.2 and 1.3 bits per word. Let’s say 1.25 bits per word then. At that entropy rate, each word disambiguates only about 2.4 possibilities on average!
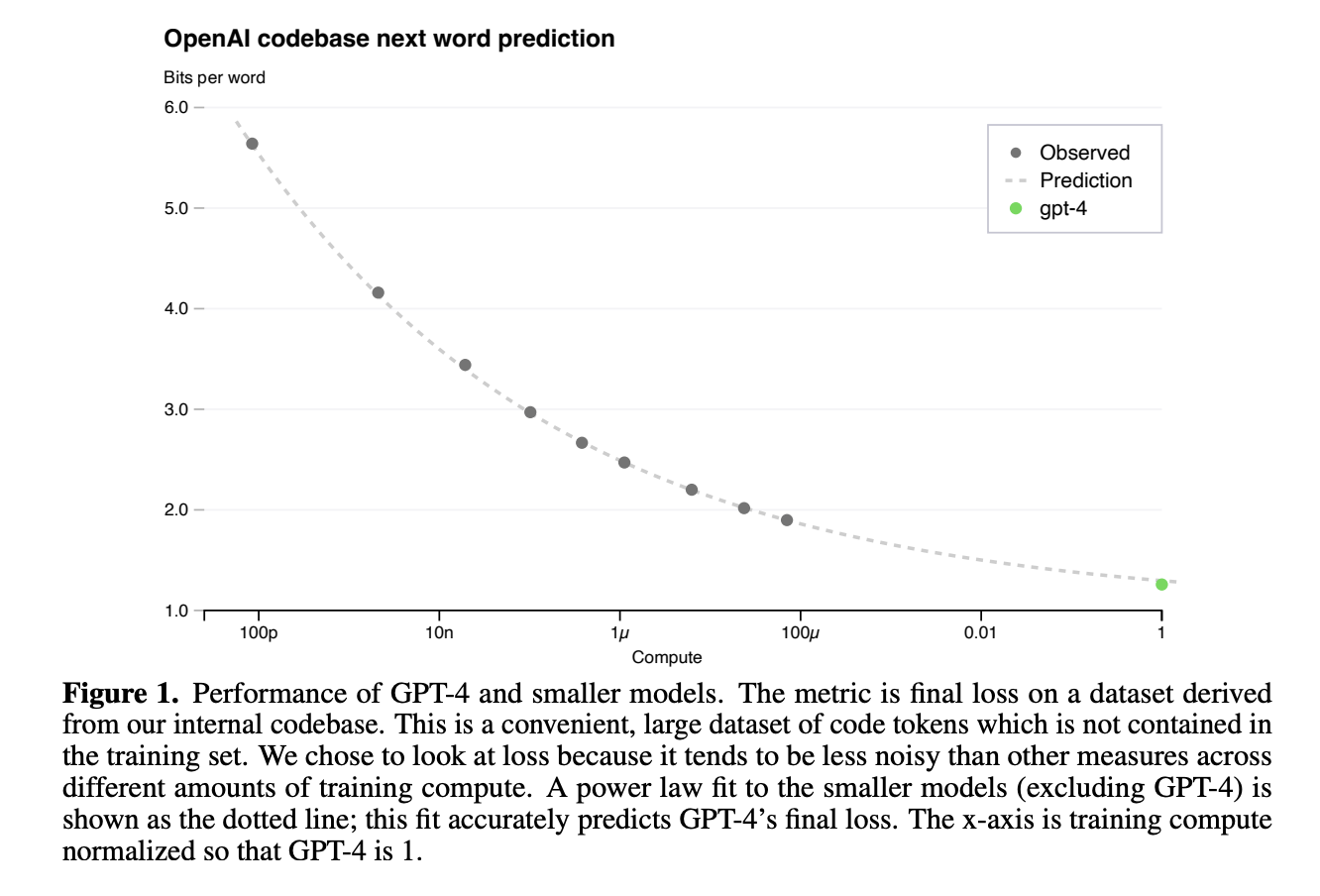
That seems very, very low but … plausible. Perhaps a model of natural language semantic unit (not necessarily a word) tends to distinguish among 2 opposing possibilities, for easy mental processing, you know things like black vs. white, high vs. low, large vs. small. The extra 0.4 possibilities may be grammatical information that attaches as free-rider onto English words. Any lower than 2 possibilities per word seems improbably low and inefficient as a communication mechanism. So if these models are for real, we must be getting very very close to the true lower bound here, and consequently, optimal model performance on English language modeling. It also nicely confirms Shannon’s thesis (in my attribution) that any source is statistical, and merely by using larger and larger contexts, its generation can be arbitrarily realistic.
